
Spark DataframeでUPSERTを行う
[English]
本記事は完全に正しいかは不明です。
この記事に書かれた内容がおかしいと気づいた方は教えてください。
2つのCSVファイルがあり、下図のようなUPSERTを行いたい場合のサンプルコード。
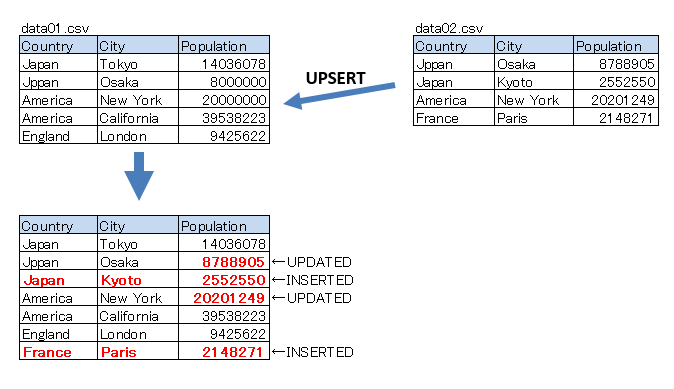
■サンプルNo.1
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df1.join(df2, ['Country','City'], 'left_anti')
df = df.unionAll(df2)
df.write.option("header","true").format("csv").save("output")
■サンプルNo.2
別の方法(以下のコードは、意図通り動いたり、動かなかったりします。
Sparkが1つのパーティションで動いた場合のみ、意図した通りに動く)
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df2.unionAll(df1)
df = df.dropDuplicates(['Country','City'])
df.write.option("header","true").format("csv").save("output")
■サンプルNo.3
以下のコードは dropDuplicates()を使っても、おそらく意図通り動く(確証はないです)
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df2.unionAll(df1)
df = df.dropDuplicates(['Country','City'])
df=df.coalesce(1)
df.write.option("header","true").format("csv").save("output")
■サンプルNo.2とNo3.の違い
Sparkは「遅延評価」を行うため、以下の処理を呼び出したときには、
df = df2.unionAll(df1) df = df.dropDuplicates(['Country','City'])
実際にはまだ処理が行われておらず、以下の処理を呼び出したときに初めて実行されます。
df.write.option("header","true").format("csv").save("output")
そのため、出力処理を行う直前に、coalesce(1)でパーティションを1に固定する命令を与えることで、
常に1パーティションで動くため、意図通りに動くと推測されます。