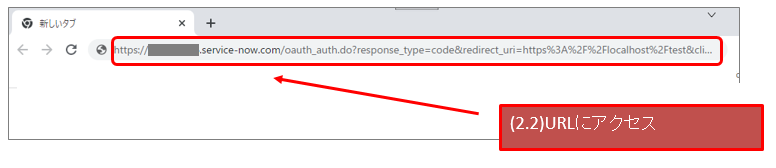
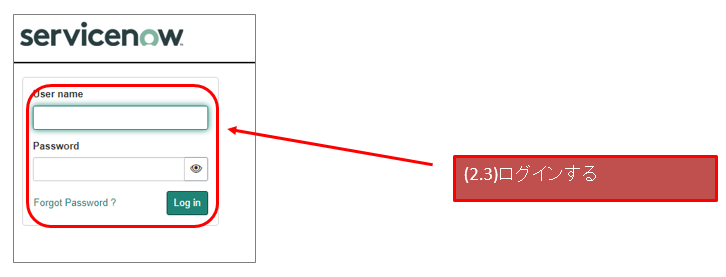
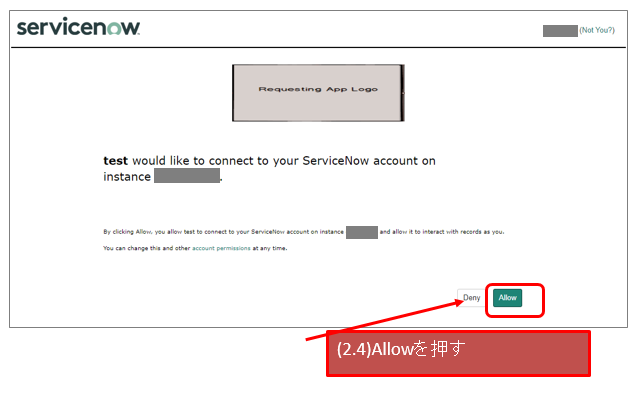
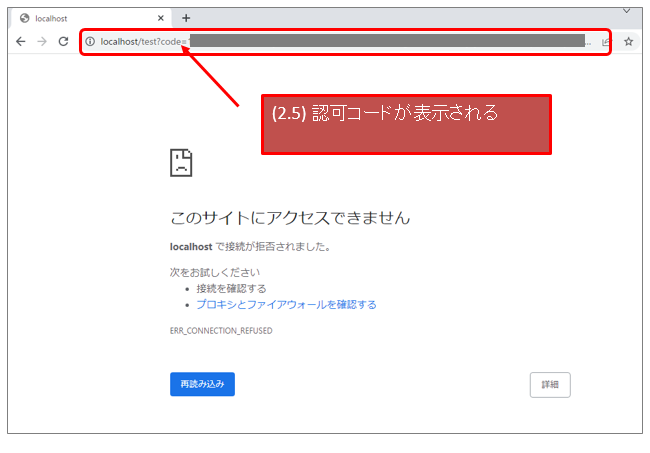
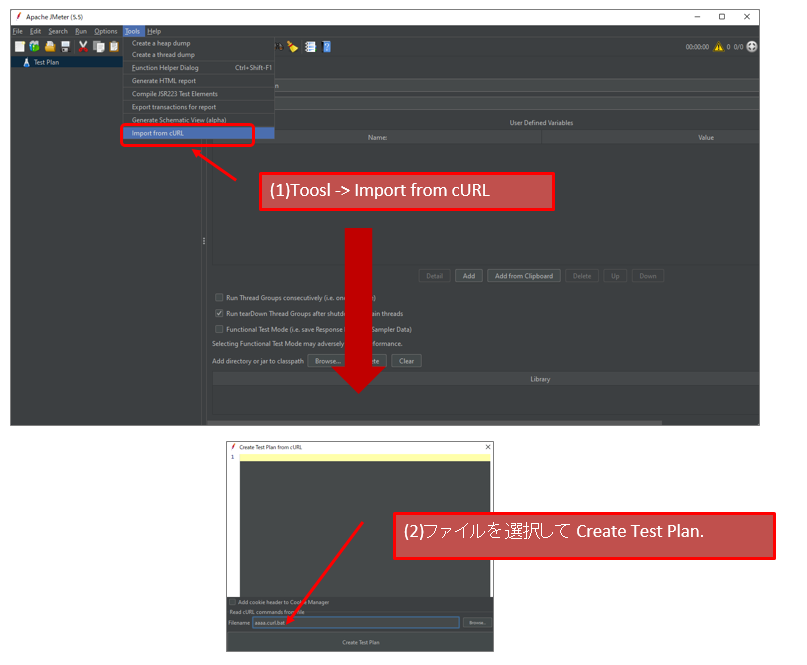
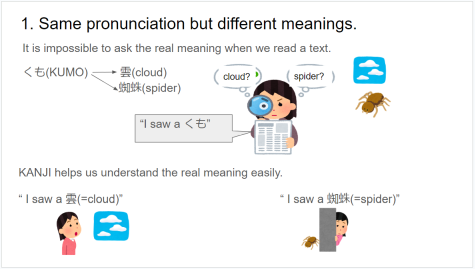
自前のSAML IdPを作成する
何らかのWebシステムを構築し、ログインをSAMLで実現したい場合、開発環境をどうするか。
開発環境は、任意のユーザとしてログインできる必要がある。しかし、開発環境特有の特殊なログインだと本番環境で起きる問題を事前に洗い出せない場合があるので、本物のIDPと同じ動きが可能な、開発環境に使用できるSAML IdPを使用したいと思うかもない。そこで、自分専用のSAML IdPを立ち上げる手順を紹介する。
■1. 環境作成の概要
サンプルとして以下のような環境を作成する。
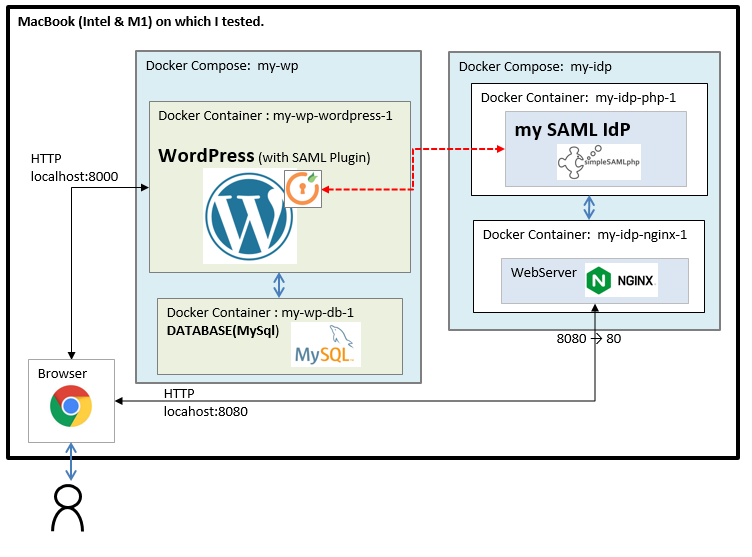 (1)WordPress環境を作成し、それと連携する独自 IdP を立ち上げる。
(1)WordPress環境を作成し、それと連携する独自 IdP を立ち上げる。
(2)WordPressのSAMLプラグインは miniOrange SAML 2.0 SSO Pluginを使用する。
(3)独自IdPは SimpleSAMLphp を使用する。
(4)上記環境は、Dockerを使って作成する。
(miniOralge SAML 2.0 SSO Plugin の無料版は、
WordPress上に存在しないユーザが SAML認証をパスしたら、自動的にそのユーザアカウントが生成される)
■2. 環境構築
必要なプログラムやシェルを以下に用意したのでそれを使用して説明する(内容の詳細は後述する)
(1)以下から、my-env.tgzをダウンロードする。
https://github.com/hidemiubiz/public/blob/main/SAML/my-env.tgz
(2)適当なフォルダ配下で解凍する。
(3)独自IdP(my-idp)の構築
(3.1)Docker Composeを使用して独自SAML IdP環境を作成
cd my-env/my-idp docker-compose up -d
(3.2)SAML連携で使用する公開鍵、秘密鍵を作成する
docker exec -it my-idp-php-1 /bin/bash cd /var/www/html /bin/sh prepare-env.sh
–> ここで作成された、my.crt (公開鍵)の内容をメモしておく。
(/var/www/html配下に、公開鍵、秘密鍵が置かれてしまう!! デモなので考慮しないが本来は別の場所に配置すべき)
(4)WordPress 環境の構築
(4.1)Docker Compose を使用してして作成する
cd my-env/my-wp docker-compose up -d
(4.2)WordPressのインストール
http://localhost:8000/wp-admin にアクセスし、指示に従ってWordPressをインストールする。
(言語を選んで、次にアカウントを1個作るだけ)
(4.3)SAML Pluginのインストール
(4.3.1)http://localhost:8000/wp-admin にアクセスし、上記(4.2)で作ったアカウントでログイン
(4.3.2)プラグイン -> 新規追加で新規追加ボタンを押す
(4.3.3)SAML で検索し、SAML Single Sign On -SSO Loginをインストールし有効化 (4.4)SAML Pluginの設定
(4.4)SAML Pluginの設定
(4.4.1)minOrange SAML 2.0 SSOをクリック
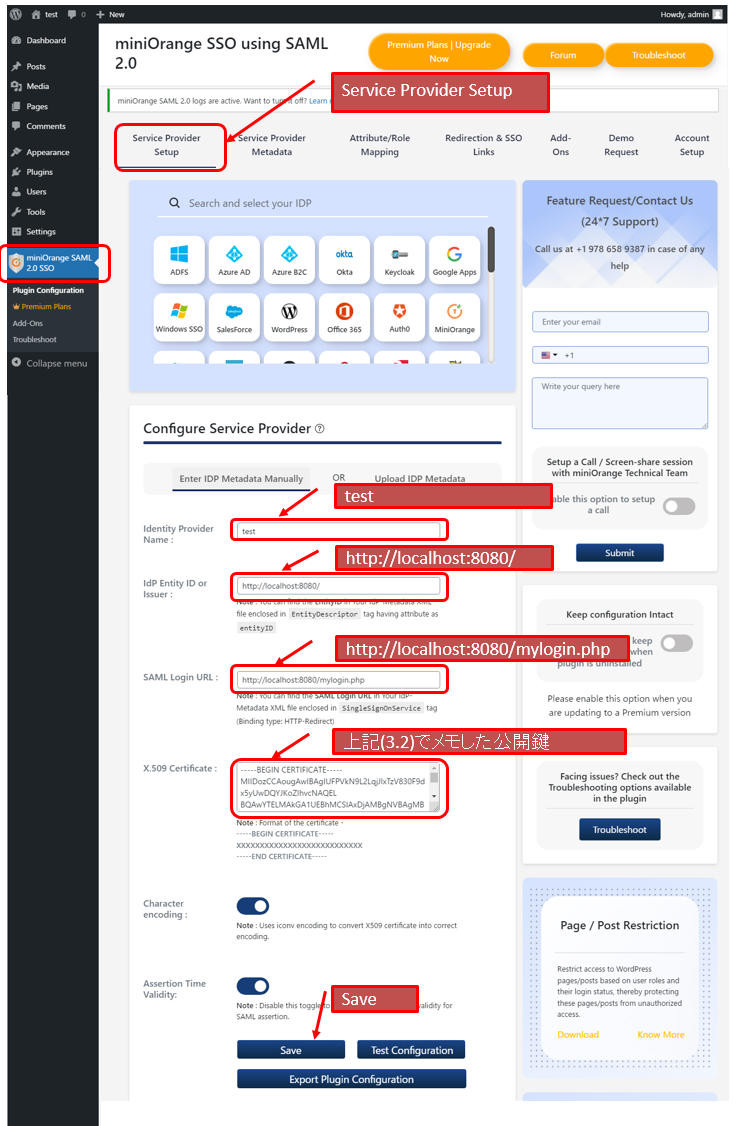
(4.4.2)Servie Provider Setupタブで以下を設定
Identity Provider Name: test Idp Entity ID or Issuer: http://localhost:8080/ SAML Login URL: http://localhost:8080/mylogin.php X.509 Certificate: 上記(3.2)でメモした公開鍵
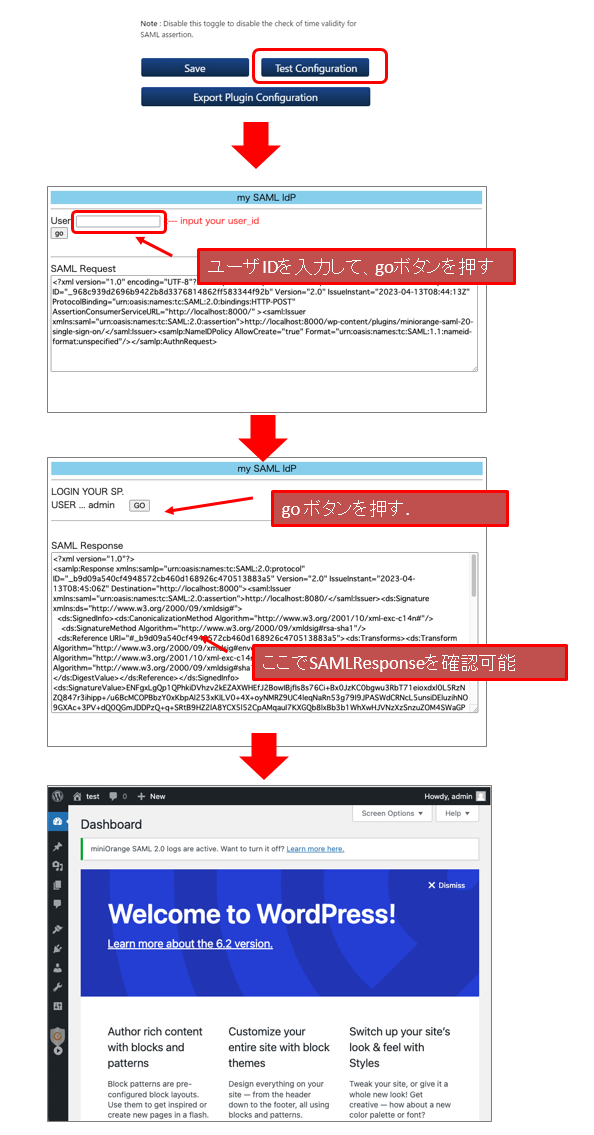
(4.4.3)Test Configurationで動作確認
■3. my-env.tgzについて
下図のファイル構成になっている。
my-env/
|--my-idp/
| |--docker-compose.yml
| |--php/
| | |--php.ini
| | |--Dockerfile
| |
| |--nginx/
| | |--nginx.conf
| |
| |--www/
| |--html/
| |--mysaml.php
| |--mylogin.php
| |--makecert.sh
|
|--my-wp/
|--docker-compose.yml
・my-env/my-idp/docker-compose.yml
自前のIdP環境を構築するdocker-comopse設定。webサーバとしてnginx、php環境を立てる。
version: '3'
services:
nginx:
image: nginx:latest
ports:
- 8080:80
volumes:
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf
- ./www/html:/var/www/html
depends_on:
- php
php:
build: ./php
volumes:
- ./www/html:/var/www/html
・my-env/my-idp/php/php.ini
date.timezone = "Asia/Tokyo"
・my-env/my-idp/www/html/makecet.sh
自前のIdPが使用する公開鍵と秘密鍵を生成するシェルスクリプト。
!/bin/sh
CN=my
PASSWORD=abcdefgxyz
SJ="/C=JP/ST=Tokyo/L=Minato-ku/O=hidemiu/OU=hidemiu/CN=$CN"
openssl genrsa -des3 -passout pass:${PASSWORD} -out ${CN}.key 2048
openssl rsa -passin pass:${PASSWORD} -in ${CN}.key -out ${CN}.key
openssl req -new -sha256 -key ${CN}.key -out ${CN}.csr -subj "$SJ"
openssl req -x509 -in ${CN}.csr -key ${CN}.key -out ${CN}.crt -days 3650
・my-env/my-idp/www/html/mylogin.php
https://github.com/hidemiubiz/public/blob/main/SAML/my-env/my-idp/www/html/mylogin.php
SP(WordPress)からSAMLRequestを受け取り、それをformに保持し、ログインするユーザアカウントを指定する画面のphp。
・my-env/my-idp/www/html/mysaml.php
https://github.com/hidemiubiz/public/blob/main/SAML/my-env/my-idp/www/html/mysaml.php
SAMLRequestとログインするユーザアカウントを受け取りSAMLレスポンスを生成し、SP(WordPress)に送信する画面のphp。
・my-env/my-idp/php/Dockerfile
FROM php:7.2-fpm COPY php.ini /usr/local/etc/php/ RUN docker-php-ext-install pdo_mysql
・my-wp/docker-compose.xml
WordPress環境のDocker-Compose設定。
version: '3'
services:
db:
image: mysql:5.7
platform: linux/amd64
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: somewordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "8000:80"
restart: always
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
volumes:
db_data:
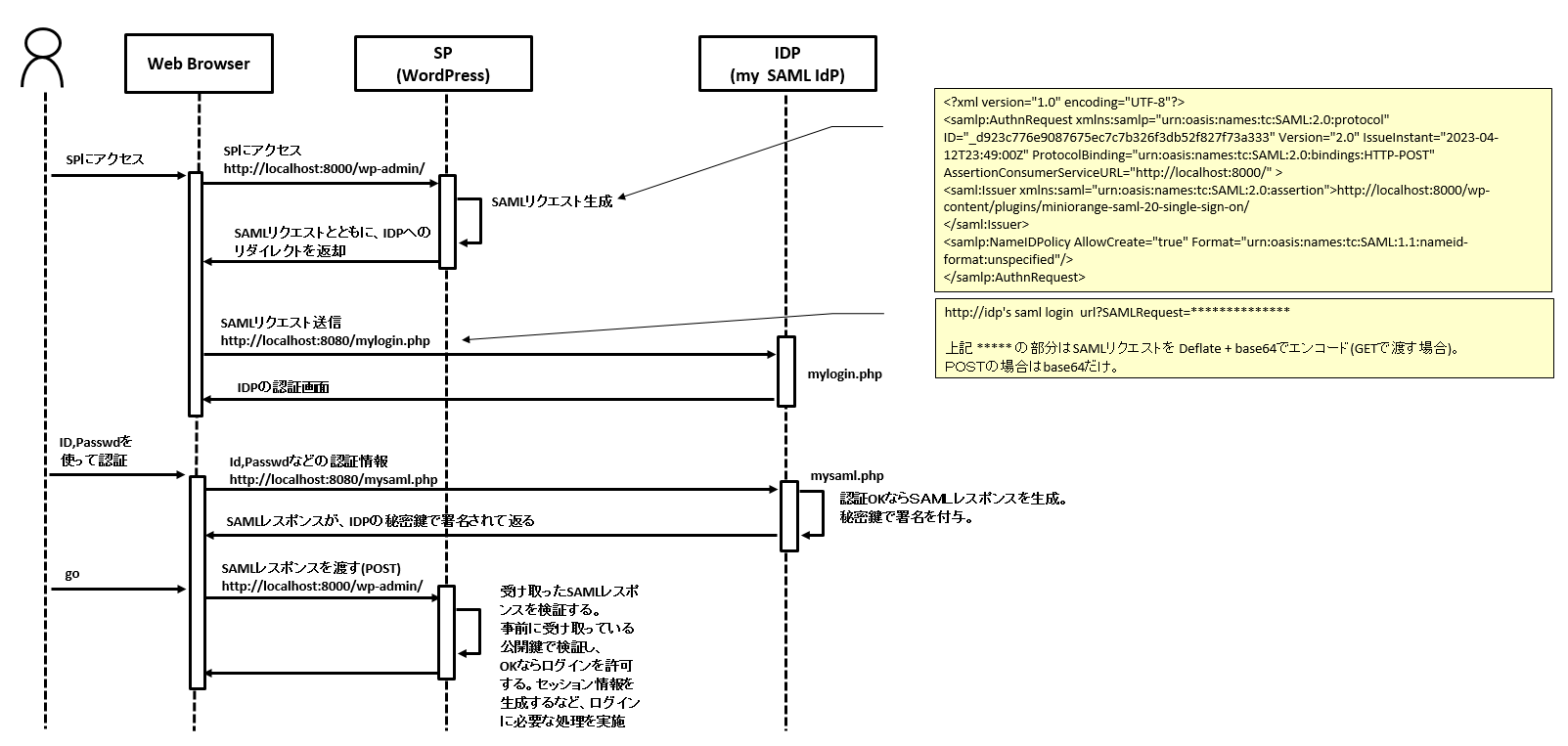
■4. 本環境のSAMLによる認証シーケンス