
How to UPSERT using Spark Dataframe
I am not sure if this article has any problem. If you found something wrong in this article. please let me know.
you have 2 csv data files and want to upsert as follows.
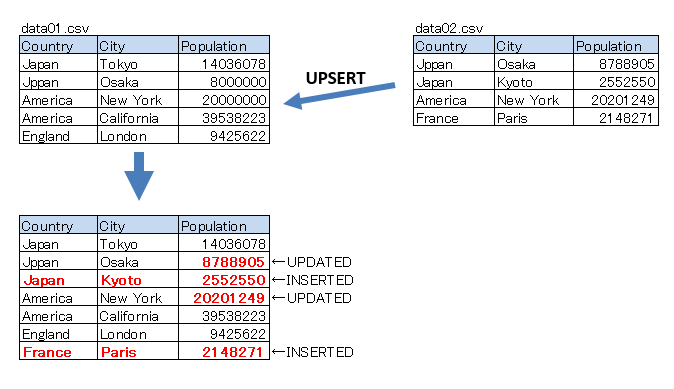
■Sampe Code No.1
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df1.join(df2, ['Country','City'], 'left_anti')
df = df.unionAll(df2)
df.write.option("header","true").format("csv").save("output")
■Sample Code No.2
Another example(this code is sometimes work intensionally, But sometimes doesn’t work intensionally.
It depends on how many partitions the program execute)
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df2.unionAll(df1)
df = df.dropDuplicates(['Country','City'])
df.write.option("header","true").format("csv").save("output")
■Sample Code No.3
this code will probably work intensionally(sorry, no guarantee).
df1 = spark.read.option("header","true").csv("data01.csv")
df2 = spark.read.option("header","true").csv("data02.csv")
df = df2.unionAll(df1)
df = df.dropDuplicates(['Country','City'])
df=df.coalesce(1)
df.write.option("header","true").format("csv").save("output")
■Difference between No2. and No.3 code is the following place.
I think Spark is “Lazy Evaluation”. So, When you call the folowing code.
df = df2.unionAll(df1) df = df.dropDuplicates(['Country','City'])
Spark Dataframe doesn’t work actually yet.It works when the following code was executed.
df.write.option("header","true").format("csv").save("output")
So, I guess the Sample Code No.3 forced Dataframe work with 1 partition,and then, dropDuplicaets() work intentionally.