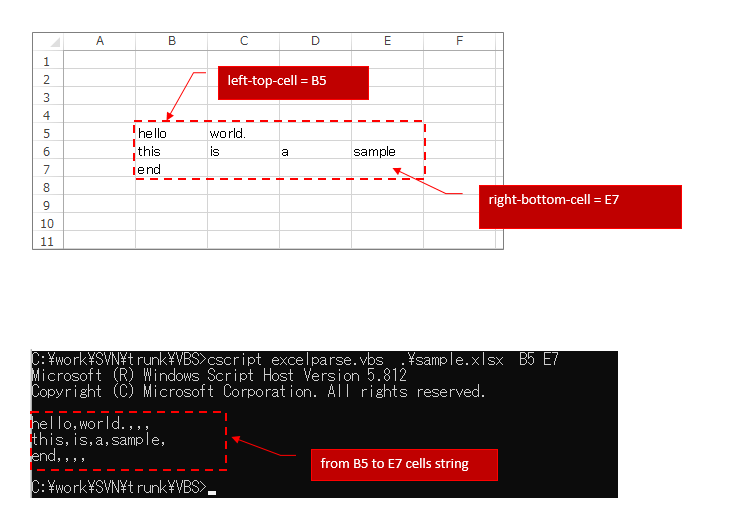
How to create your own SAML IdP
How you do test your Web System’s Authentication, if it uses SAML Authentication?
You might want your own SAML IdP for test purpose.
This article shows how to create your own SAML IdP.
■1. Overview of your own SAML IdP environment.
Create an environment as below.
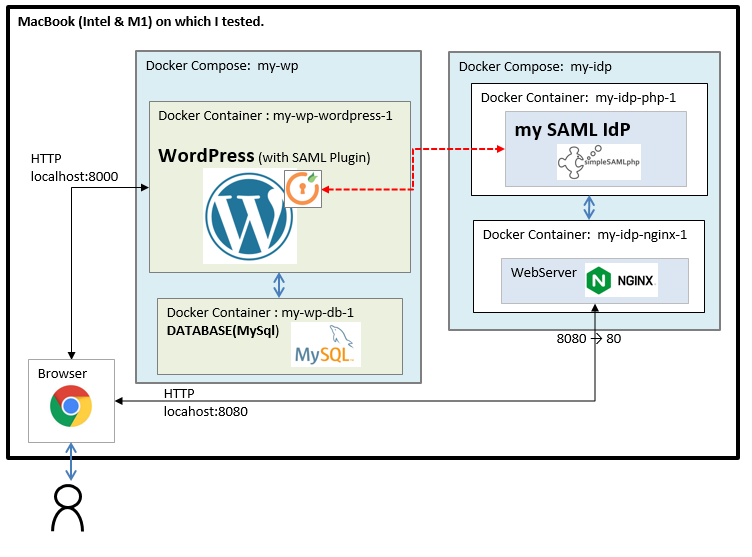
(1)Create WordPress that connect with your own IdP.
(2)Use miniOrange SAML 2.0 SSO Plugin for your WordPress.
(3)Use SimpleSAMLphp for your own IdP.
(4)Create those environment using Docker.
(miniOrange SAML 2.0 SSO Plugin for free creates new account automatically when your own Idp send the valid SAML Response)
■2. How to create the environment.
You can use archived file which contains needed files. (More on detail of these fiels later)
(1)download my-env.tgz from the link below.
https://github.com/hidemiubiz/public/blob/main/SAML/my-env.tgz
(2)Extrace my-env.tgz wherever you want to create.
(3)Create your own IdP.
(3.1)Create your own IdP using Docker Compose.
cd my-env/my-idp docker-compose up -d
(3.2)Create public key and private key.
docker exec -it my-idp-php-1 /bin/bash cd /var/www/html /bin/sh prepare-env.sh
save my.crt’s content. you have to use this later.
(private key is placed in /var/www/html. this is just a demo. but you had better place this file in other folder.)
(4)Create WordPress.
(4.1)Create WordPress using Docker Compose.
cd my-env/my-wp docker-compose up -d
(4.2)Install WordPress by following the instruction.
Access “http://localhost:8000/wp-admin” and follow the instruction to install your WordPress.
(You only have to choose the language and create 1 acccount.)
(4.3)Install SAML Plugin to your WordPress.
(4.3.1)access “http://localhost:8000/wp-admin” with using the acount that you created.
(4.3.2)Select Plugin -> New.
(4.3.3)Search “SAML” , install “SAML Single Sign On-SSO Login” and activate it.

(4.4)SAML Plugin setting .
(4.4.1)Select miniOrange SAML 2.0 SSO.
(4.4.2)Select “Service Provider Setup” tab and set parameters as follows.
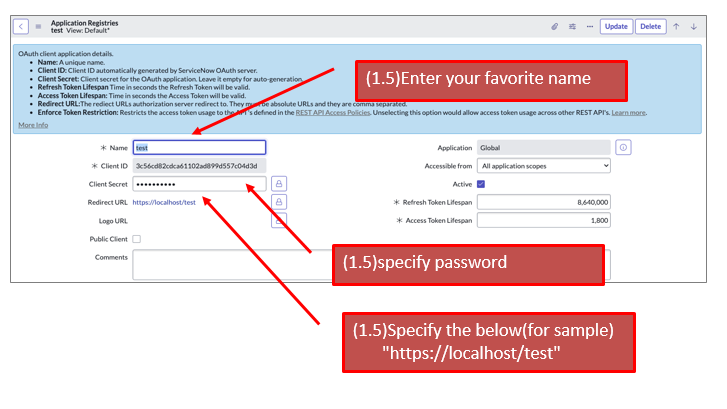
Identity Provider Name: test Idp Entity ID or Issuer: http://localhost:8080/ SAML Login URL: http://localhost:8080/mylogin.php X.509 Certificate: 上記(3.2)でメモした公開鍵
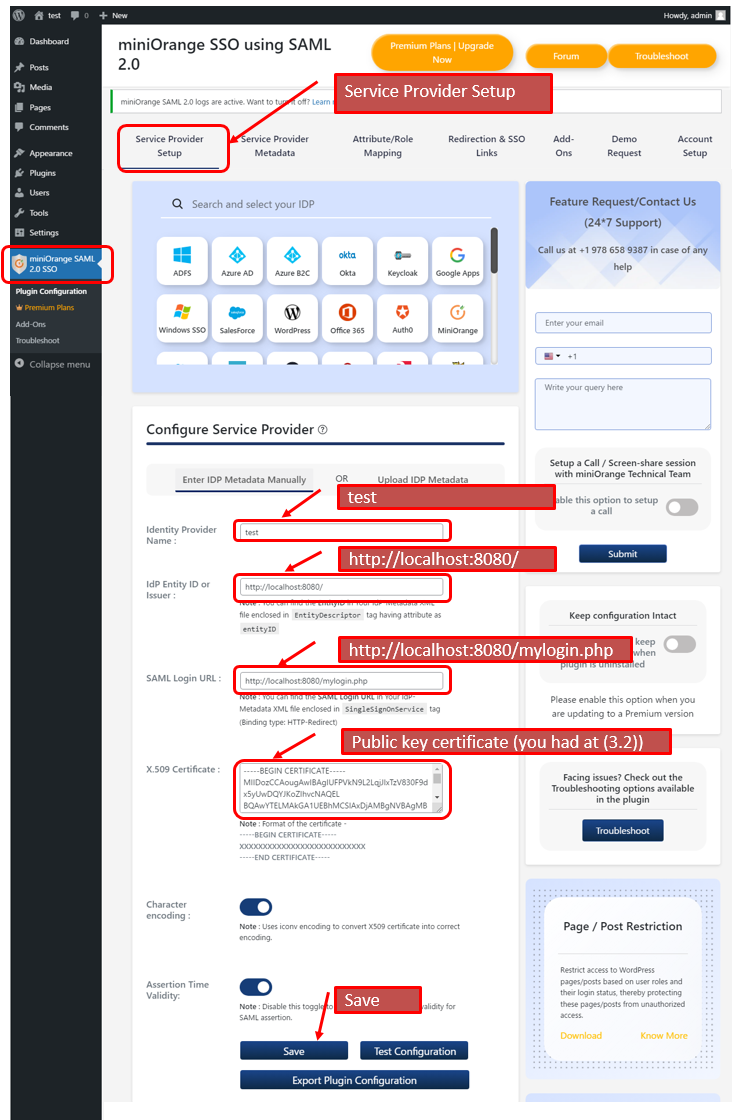
(4.4.3)Test Configuration
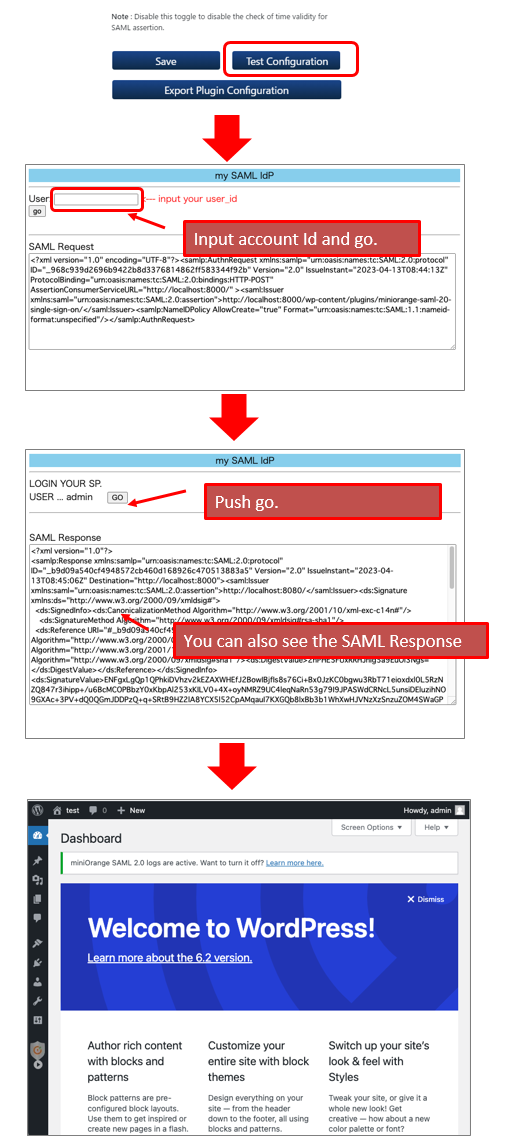
■3. About my-env.tgz
my-env/
|--my-idp/
| |--docker-compose.yml
| |--php/
| | |--php.ini
| | |--Dockerfile
| |
| |--nginx/
| | |--nginx.conf
| |
| |--www/
| |--html/
| |--mysaml.php
| |--mylogin.php
| |--makecert.sh
|
|--my-wp/
|--docker-compose.yml
・my-env/my-idp/docker-compose.yml
Docker-Compose setting for my SAML IdP.
version: '3'
services:
nginx:
image: nginx:latest
ports:
- 8080:80
volumes:
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf
- ./www/html:/var/www/html
depends_on:
- php
php:
build: ./php
volumes:
- ./www/html:/var/www/html
・my-env/my-idp/php/php.ini
date.timezone = "Asia/Tokyo"
・my-env/my-idp/www/html/makecet.sh
Shell script to create my SAML IdP’s public key an private key.
!/bin/sh
CN=my
PASSWORD=abcdefgxyz
SJ="/C=JP/ST=Tokyo/L=Minato-ku/O=hidemiu/OU=hidemiu/CN=$CN"
openssl genrsa -des3 -passout pass:${PASSWORD} -out ${CN}.key 2048
openssl rsa -passin pass:${PASSWORD} -in ${CN}.key -out ${CN}.key
openssl req -new -sha256 -key ${CN}.key -out ${CN}.csr -subj "$SJ"
openssl req -x509 -in ${CN}.csr -key ${CN}.key -out ${CN}.crt -days 3650
・my-env/my-idp/www/html/mylogin.php
https://github.com/hidemiubiz/public/blob/main/SAML/my-env/my-idp/www/html/mylogin.php
Receive SAMLRequest from SP(WordPress). Hold the request and receive account Id that you want to login.
・my-env/my-idp/www/html/mysaml.php
https://github.com/hidemiubiz/public/blob/main/SAML/my-env/my-idp/www/html/mysaml.php
Create SAMLRequest with using Login Id and SAMLRequest, then go to SP(WordPress) login page.
・my-env/my-idp/php/Dockerfile
FROM php:7.2-fpm COPY php.ini /usr/local/etc/php/ RUN docker-php-ext-install pdo_mysql
・my-wp/docker-compose.xml
Docker-compose setting for WordPress.
version: '3'
services:
db:
image: mysql:5.7
platform: linux/amd64
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: somewordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "8000:80"
restart: always
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
volumes:
db_data:
■4. SAML Authentication sequence of this environment.
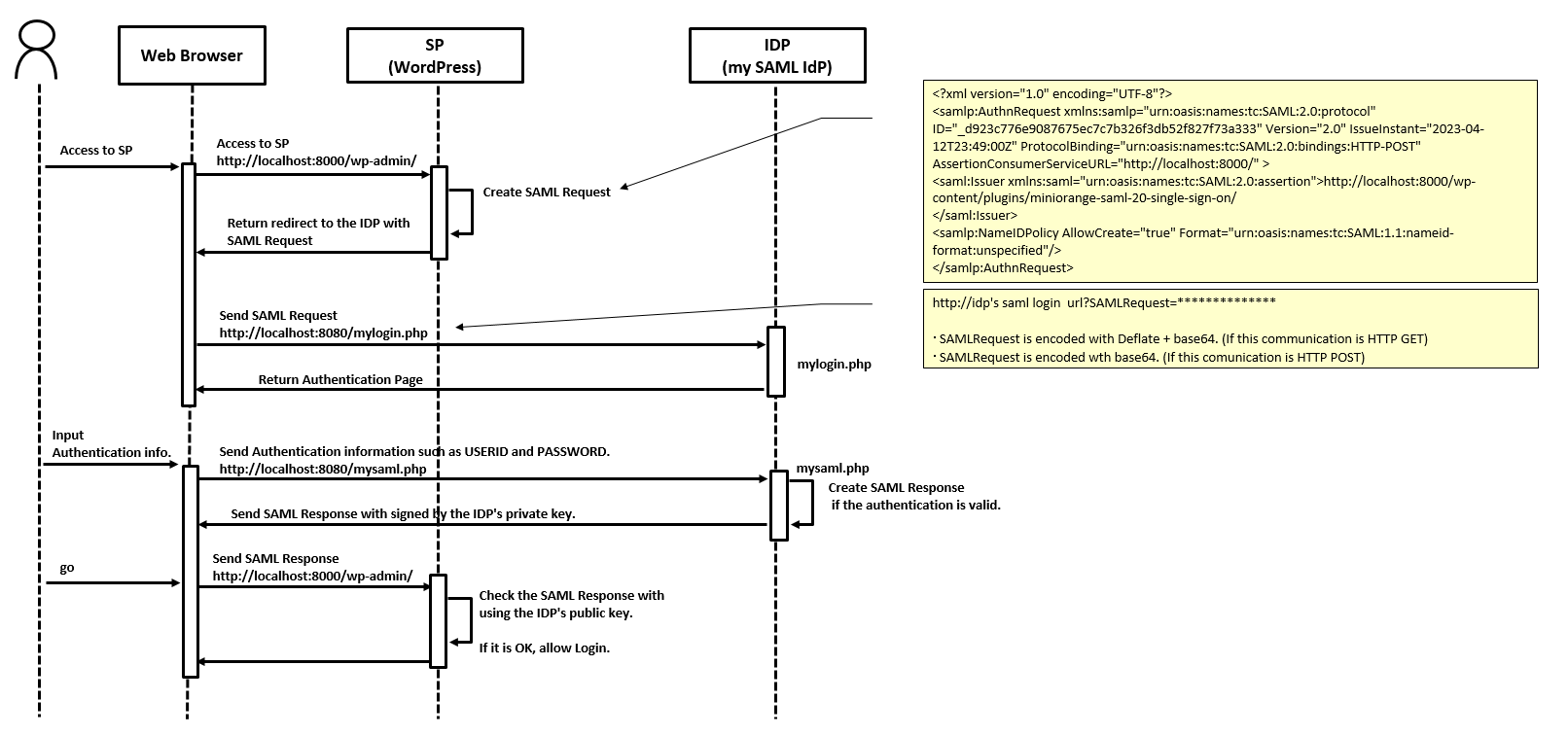
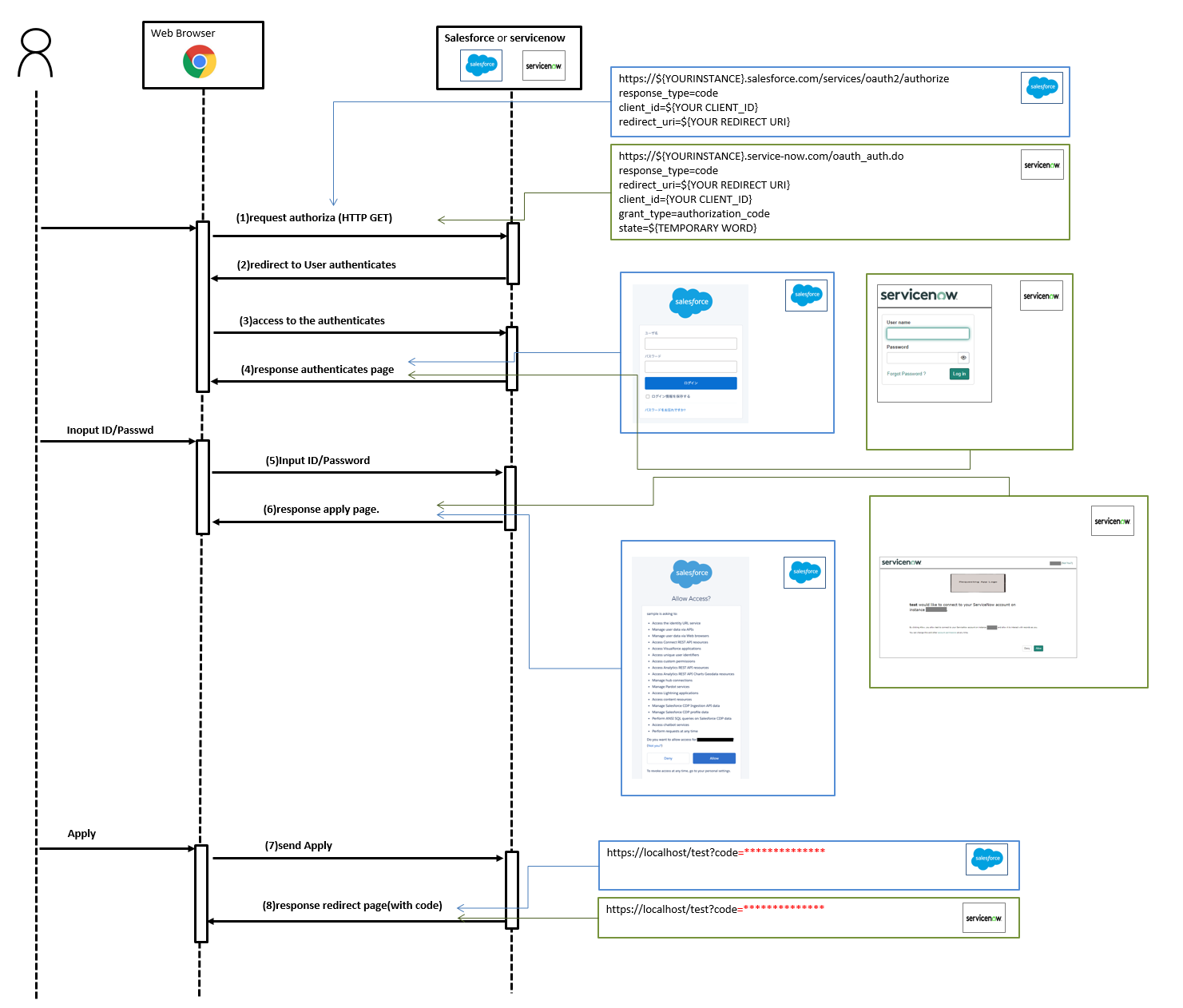
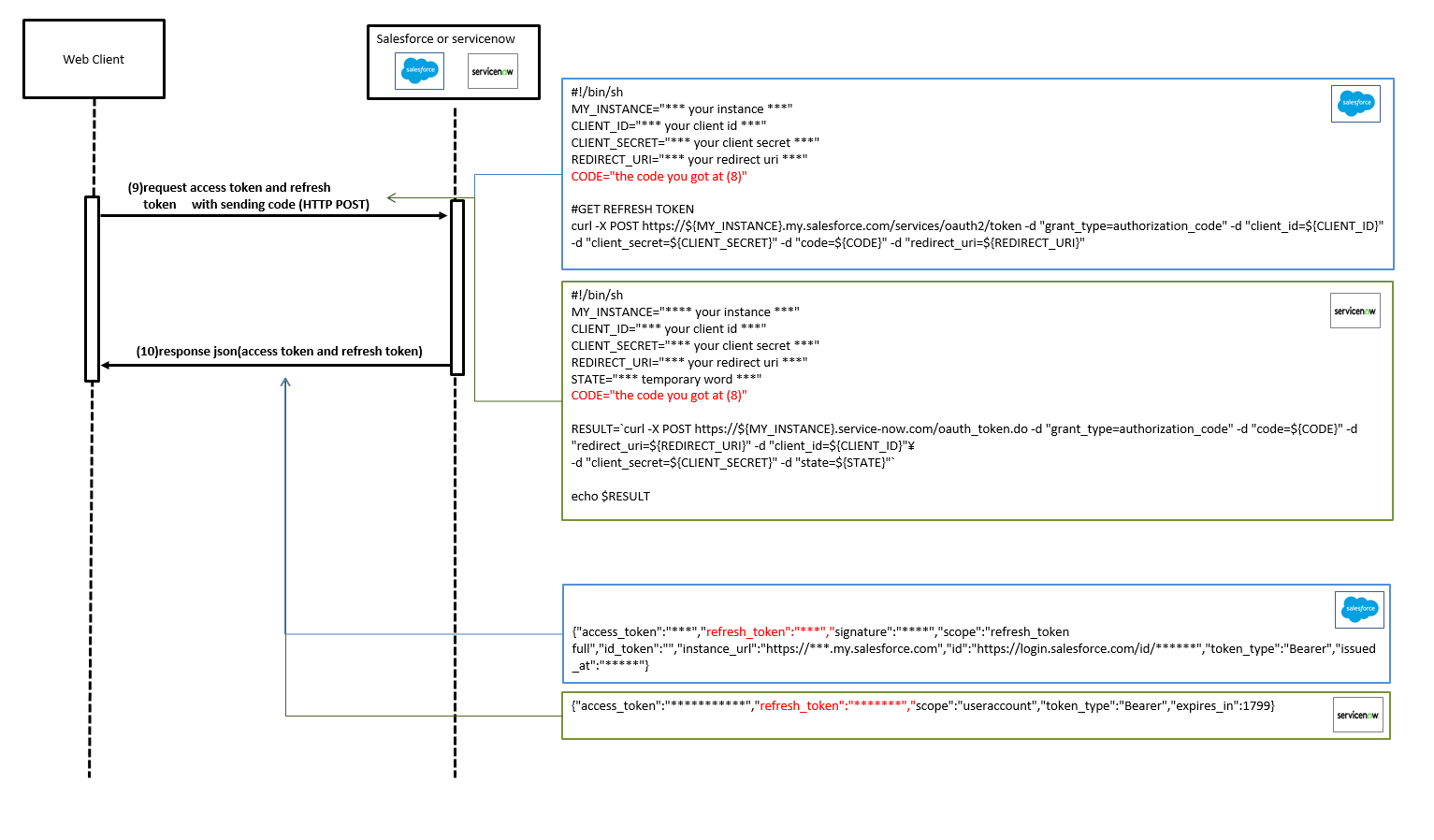
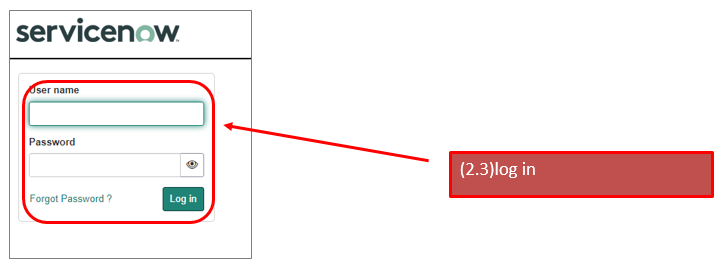
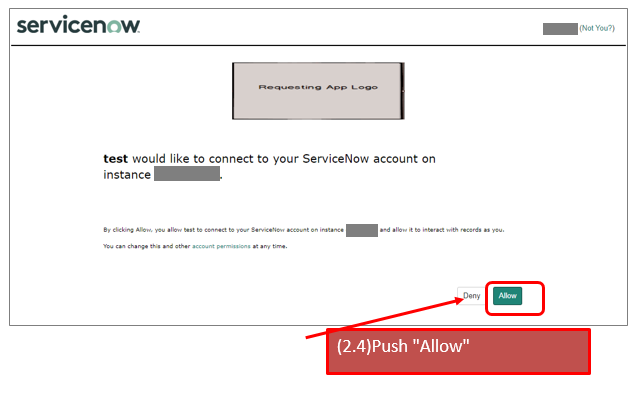
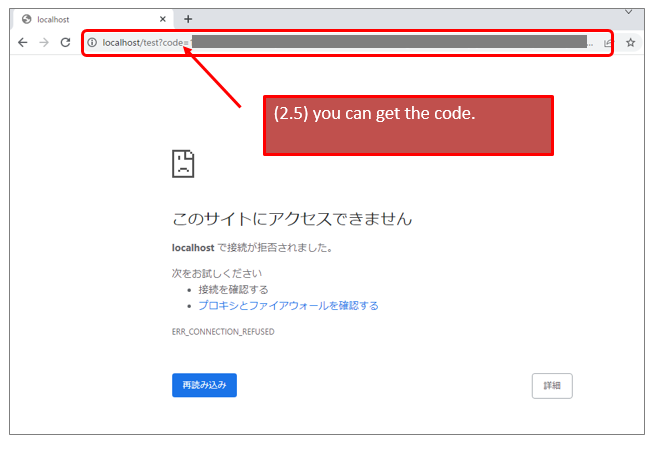
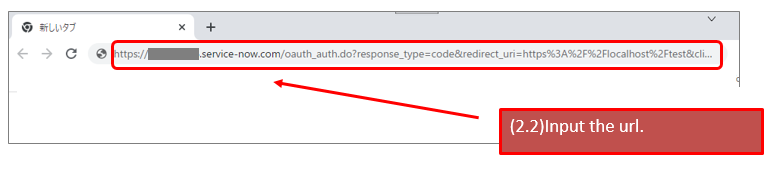 https://${YOUR_INSTANCE}.service-now.com/oauth_auth.do?response_type=code&redirect_uri=https%3A%2F%2Flocalhost%2Ftest&client_id=${YOUR_CLIENT_ID}&grant_type=authorization_code&state=123
* redirect_url ... https://localhost/test (you can apply the url that you specified on your endpoint.)
* state ... 123(you can apply your favorit word. this is just a sample)
https://${YOUR_INSTANCE}.service-now.com/oauth_auth.do?response_type=code&redirect_uri=https%3A%2F%2Flocalhost%2Ftest&client_id=${YOUR_CLIENT_ID}&grant_type=authorization_code&state=123
* redirect_url ... https://localhost/test (you can apply the url that you specified on your endpoint.)
* state ... 123(you can apply your favorit word. this is just a sample)